July 2, 2026
Author: Sarang Brahme
Principal Architect – Data and AI
Long View
RAG AI on MS Fabric: Building Knowledge-Powered AI Solutions
In today's fast-paced digital landscape, businesses have abundant data, but they lack meaningful insights. Large Language Models (LLMs) are plenty and their capabilities abound, and still, they often struggle with outdated information, or they lack context-specific knowledge.
RAG or Retrieval-Augmented-Generation, aims to solve this quandary. This approach bridges the gap between language understanding and your company's unique information ecosystem. RAG is more of a pattern than a technology by itself, and naturally it needs a framework or platform to run with. This is where Microsoft Fabric enters the picture. With Fabric's robust capabilities, we can build RAG solutions that transform how organizations interact with their data. Whether you're looking to create an intelligent chatbot for customer service, a powerful research assistant for your team, or a dynamic knowledge management system, RAG AI on Microsoft Fabric opens a whole new set of possibilities!
In this technical deep dive, we'll explore how to implement RAG AI with Microsoft Fabric. We'll walk through the architecture, implementation steps, and optimization techniques that will empower you to create AI solutions that are not just smart, but truly knowledgeable about your business. Buckle up as we embark on a journey to revolutionize how AI serves your organization's needs.
Understanding RAG AI
Retrieval Augmented Generation (RAG) is an AI framework that enhances the capabilities of large language models (LLMs) by grounding them with external, up-to-date information. The architecture of RAG addresses the fundamental limitations of traditional LLMs, which typically rely on static training data and can produce responses that are outdated or inaccurate.
Let's go through the components of RAG AI:
Retrieval:
The retrieval component is responsible for finding relevant information from a knowledge base or external data source in response to a user query. It involves:
1. Query Encoding: The user's input is transformed into a numerical representation (embedding) using models like BERT or GPT.
2. Vector Search: The system searches through a vector database to find documents or text chunks that are semantically similar to the query.
3. Ranking and Filtering: Retrieved information is ranked based on relevance, typically selecting the top N most relevant documents
Augmentation:
The augmentation component enhances the retrieved information and prepares it for the generation phase:
1. Contextual Embedding: Retrieved documents are converted into numerical embeddings to allow the model to process their content effectively
2. Fusion: The retrieved information is combined with the original query to create a more comprehensive prompt for the language model
3. Prompt Engineering: Techniques are applied to effectively communicate the augmented context to the LLM
Generation:
The generation component uses a large language model (LLM) to produce a response based on the augmented prompt:
1. Context Processing: The LLM analyzes the augmented prompt, which includes both the original query and the retrieved information
2. Response Generation: The model generates an answer that leverages both its pre-trained knowledge, and the additional context provided
Embedding Model:
An embedding model converts text data into numerical vector representations, enabling efficient storage and retrieval of information in vector databases.
Document Embedding: Converts external documents into vector representations for storage in the vector database
Query Embedding: Transforms user queries into vector form for similarity matching
Vector Database:
1. Storage: Holds the embedded representations of documents or other data sources
2. Retrieval: Enables fast and efficient similarity searches to find relevant information
Re-ranker:
Some RAG systems include a re-ranker component that evaluates and scores the retrieved documents based on their relevance to the original query, helping to prioritize the most pertinent information for augmentation.
1. Score-based Re-rankers: Aggregate and reorder candidate lists using weighted scoring or Reciprocal Rank Fusion
2. Neural Network-based Re-rankers: Use deep learning to analyze query-document relevance and refine search results
3. Relevance Scoring: Provides more precise relevance scores, helping to filter out less relevant information before it reaches the LLM
Let's look at the RAG AI pattern with a simple block diagram:
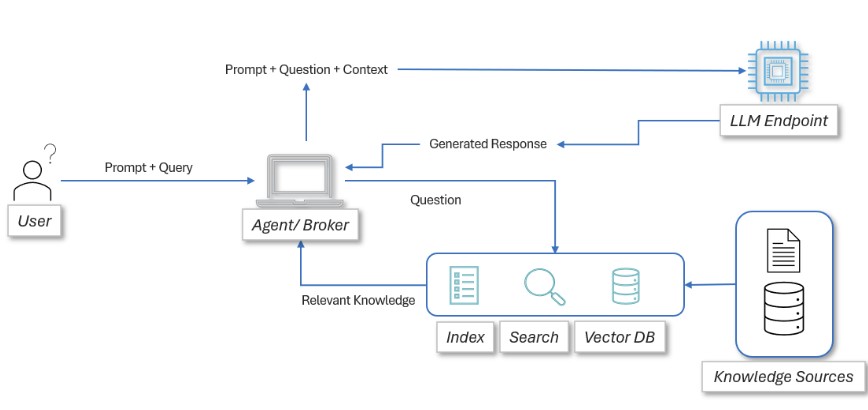
Use Cases for RAG AI:
By 2025, RAG has established itself as a vital technique in creating more reliable and trustworthy AI applications across diverse fields, ranging from enterprise knowledge management systems to customer-facing chatbots. The architecture's capacity to dynamically incorporate new information ensures that AI solutions remain adaptable and responsive to evolving data landscapes.
| Content Generation | Summarization | Code Generation | Semantic Search |
| Call center analytics | Conversation summaries | Natural language to Code | Search reviews |
| Automated customer responses | Document summarization | Text instructions to Flows | Knowledge mining |
| Report generation | Trend summarization | Query data models | Internal search engine |
| Machine instructions generation | Code documentation | ||
| Marketing emails | Code debugging |
A Bit about Microsoft Fabric
Microsoft Fabric, launched in 2023, is a robust analytics platform that integrates a wide array of data workloads into a unified, seamless solution. It brings together data engineering, data factory operations, data science, real-time analytics, data warehousing, and business intelligence capabilities within a single, cohesive framework.
Central to Fabric is OneLake, a unified data lake that streamlines data management and access throughout the platform. Designed to be AI-powered, Fabric incorporates Copilot, which provides natural language assistance for tasks such as creating dataflows, drafting SQL queries, and developing reports.
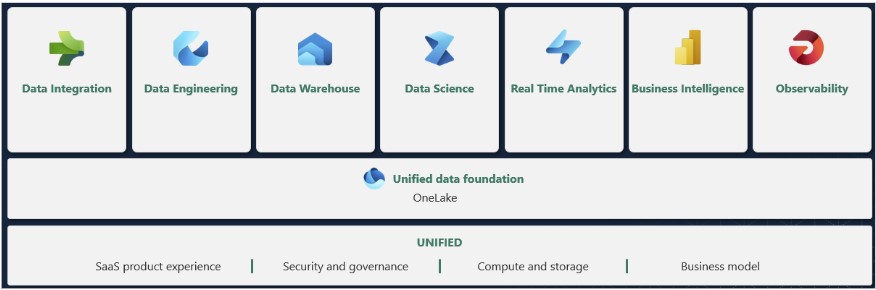
Fabric is engineered to be AI-powered, featuring Copilot integration, which offers natural language assistance to streamline complex tasks. This includes creating dataflows, writing SQL statements, and building comprehensive reports, making it easier for users to interact with and utilize their data without needing extensive technical expertise. The platform's AI capabilities facilitate a more intuitive user experience, allowing users to leverage advanced analytics and insights with greater ease.
By February 2025, Fabric has established itself as an essential tool for organizations aiming to fully harness their data's potential, offering a lake-centric, open approach that enhances data-driven decision-making and fosters AI innovation.
RAG AI with Fabric
Now with this background, let us start building the RAG AI in Microsoft Fabric.
Architecture Overview:
The RAG architecture in Microsoft Fabric typically involves the following components:
1. Data Source: Usually a Lakehouse folder containing documents (e.g., PDFs)
2. Text Processing: Extracting and chunking text from documents
3. Embedding Generation: Using Azure OpenAI's embedding model (e.g., text-embedding-ada-002)
4. Vector Database: Storing embeddings, often using Azure AI Search or Fabric Eventhouse
5. Query Processing: Converting user questions to embeddings and performing similarity search
6. Language Model: Using Azure OpenAI's GPT models (e.g., GPT-3.5-turbo or GPT-4) to generate responses
Implementation Steps
This implementation is technically involved and assumes following pre-requisites are available/ ready to use:
- Microsoft Fabric SKU - Theoretically, any level from F4 and up is good for a 'proof of concept', but it is highly recommended to start with F16 for experimentation, and F64 and above for production scenarios.
- Fabric Lakehouse - to store the input files
- Fabric Eventhouse - as vector storage and KQL database
- Fabric Notebooks - for coding with Python and other languages
- Azure Document intelligence - to convert PDF and other files into data
- Azure AI Search - for accurate search and indexing of the knowledge base
- Azure Open AI Models - separate models for embedding and completions
- Python dependencies - libraries such as Azure, Fabric, OpenAI, LangChain, etc.
Here are the steps to the first implementation.
Following code is also available at https://github.com/sarang-lvs/Fabric_RAGAI
1. Library imports:

2. Get keys and secrets for the Azure and Fabric Services - from Azure Key Vault

3. Data Preparation
Start by reading documents from your Fabric Lakehouse. For PDF files, you'll need to extract text and split it into manageable chunks. A common approach is to use a chunk size of around 1000 characters.
Repeat this for all the data files you need and upload.
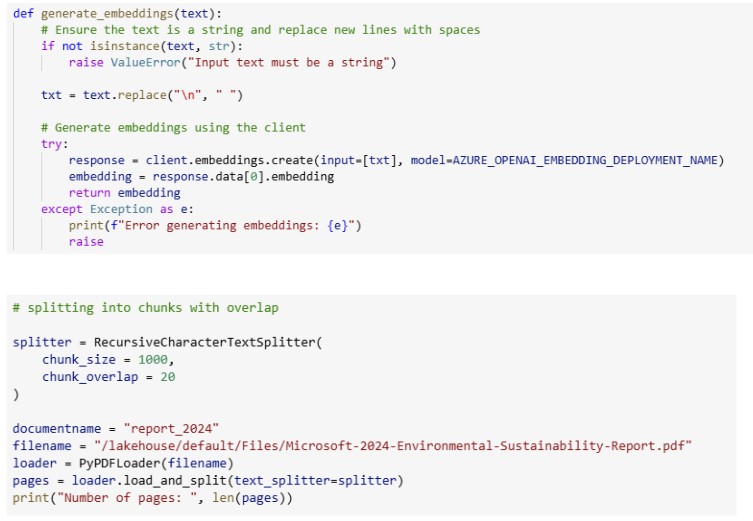
4. Save pages in a data frame


5. Create embeddings with Azure OpenAI model Ada

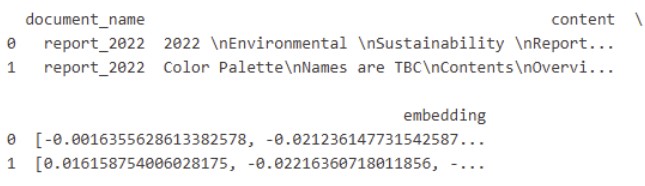
6. Create a Spark Data frame and write into the Kusto table

7. Vector Search with Kusto and Azure OpenAI
raise 

Microsoft Fabric offers multiple options for vector storage. Azure AI Search is commonly used, but Fabric Eventhouse is recommended for high-scale applications.
8. Setting final parameters and prompts
You can change these parameters based on your requirements.

9. Calling the function for the result:
Now, let us understand how this powerful tool can help in answering questions about the data, and in turn about business, especially sustainability and energy management.
RAG AI in Sustainability and Energy Management
Microsoft Fabric's integration with Retrieval-Augmented Generation (RAG) AI provides a powerful solution for sustainability and energy management companies, enabling them to optimize operations, improve decision-making, and achieve sustainability goals. By leveraging Microsoft Fabric's data integration capabilities and Azure OpenAI, the company can implement RAG to address critical use cases:
- Energy Consumption Analysis: RAG can retrieve historical energy usage data from OneLake or Azure Data Lake and combine it with real-time energy consumption metrics. This allows the company to generate actionable insights, such as identifying inefficiencies or recommending off-peak scheduling for machinery to reduce energy costs.
- Sustainability Reporting: Using RAG, the company can automate the generation of detailed sustainability reports by retrieving emissions data (e.g., Scope 1, 2, and 3 emissions) from various sources like smart meters, utility invoices, and internal databases. This simplifies compliance reporting and helps track progress toward net-zero targets.
- Renewable Energy Optimization: RAG can analyze weather forecasts, satellite imagery, and historical performance data to optimize renewable energy systems like wind turbines or solar panels. For instance, it can recommend ideal turbine placements or predict solar power generation to align with demand patterns.
- Demand Response Management: By integrating real-time grid data with historical usage patterns, RAG enables the company to optimize demand response strategies. This ensures energy distribution aligns with renewable supply while minimizing waste and balancing grid loads.
- Knowledge Management for Sustainability Goals: RAG can act as an intelligent assistant for employees by retrieving relevant documents, policies, or best practices related to sustainability initiatives. For example, it can answer questions like "What are the best practices for reducing carbon emissions in manufacturing?"
Why Use Microsoft Fabric for RAG AI Solutions?
Well, because Microsoft Fabric offers compelling advantages for implementing Retrieval-Augmented Generation (RAG) AI solutions. Here's why it stands out:
Unified Data Platform:
Fabric provides an end-to-end platform where all RAG components can exist in one ecosystem. This eliminates the need to stitch together disparate systems, reducing complexity and integration challenges. Your vector database, traditional data storage, and AI processing can all live within the same platform.
Seamless Data Integration and OneLake Data Architecture:
Fabric is great at connecting to diverse data sources critical for comprehensive RAG solutions. It offers native connectors to hundreds of data sources including SQL databases, NoSQL stores, APIs, and unstructured data repositories. This capability is essential for building knowledge bases that draw from multiple information sources. The OneLake architecture provides a unified storage layer that can simultaneously handle structured data, unstructured documents, and vector embeddings. This allows RAG solutions to maintain coherence between source documents and their vector representations without complex data pipelines.
Scalability Architecture and Cost Efficiency:
As RAG solutions grow in document volume and user queries, Fabric scales automatically. Its distributed processing capabilities can handle massive document collections and high-throughput query processing without performance degradation. By consolidating multiple tools into one platform, Fabric can significantly reduce the total cost of ownership for RAG solutions. You avoid paying for separate vector databases, document processors, and integration services.
Governance and Security Integration:
RAG solutions often involve sensitive data. Fabric's built-in governance features provide data lineage tracking, access controls, and audit capabilities that ensure compliance with organizational policies and regulatory requirements.
Enterprise-grade Reliability:
For production RAG deployments, Fabric offers enterprise-grade SLAs, disaster recovery, and high availability features that ensure consistent performance and uptime.
Semantic Search and Vector Capabilities:
Fabric's semantic search functions and vector capabilities are built directly into the platform, allowing for efficient similarity-based retrieval without needing to integrate external vector databases. This simplifies the architecture of RAG solutions.
Direct Azure Open AI Integration:
Fabric provides seamless integration with Azure OpenAI Service, allowing for straightforward deployment of RAG patterns using Microsoft's LLM offerings while maintaining data residency and security requirements.
Built-in Prompt Engineering Tools:
Fabric includes tools for prompt management, versioning, and testing—essential capabilities for developing and maintaining effective RAG systems that properly balance retrieval and generation.
Fast Collaboration Environment:
Fabric's workspace model enables data scientists, engineers, and domain experts to collaborate on RAG development. Multiple team members can simultaneously work on different aspects of the solution—some focusing on data preparation, others on prompt engineering, and others on evaluation.
Monitoring and Observability:
Fabric offers comprehensive monitoring of both the data pipeline and the AI components, providing visibility into retrieval accuracy, generation quality, and overall system performance.
These capabilities make Microsoft Fabric particularly well-suited for organizations looking to implement RAG solutions that are robust, scalable, and integrated with their existing data ecosystem.
Advanced Analytics Capabilities:
Fabric combines traditional business intelligence with modern AI capabilities. This enables sophisticated pre-processing of data before embedding, context-aware retrieval, and post-processing of LLM outputs—all critical for high-quality RAG implementations.
Next Steps and Call to Action
RAG AI in Microsoft Fabric represents a significant leap forward in data analytics and AI integration. Its ability to retrieve and generate contextually relevant information makes it a game-changer for businesses seeking to unlock the full potential of their data.
Ready to revolutionize your data analytics strategy with RAG AI? Contact me to discuss how to implement this powerful technology in your organization and drive your business forward. Let's start the conversation today!
Code repository: https://github.com/sarang-lvs/Fabric_RAGAI
Subscribe to our newsletter for the latest updates.